My last real job before becoming independent ( long story 😉 ) was leading a team developing an adaptive learning platform. The underlying proposition was the basis for a topic I identified as one of my themes. Thinking about it in the current context I realize that there’re some new twists. So here I’m reflecting on adaptive learning technology.
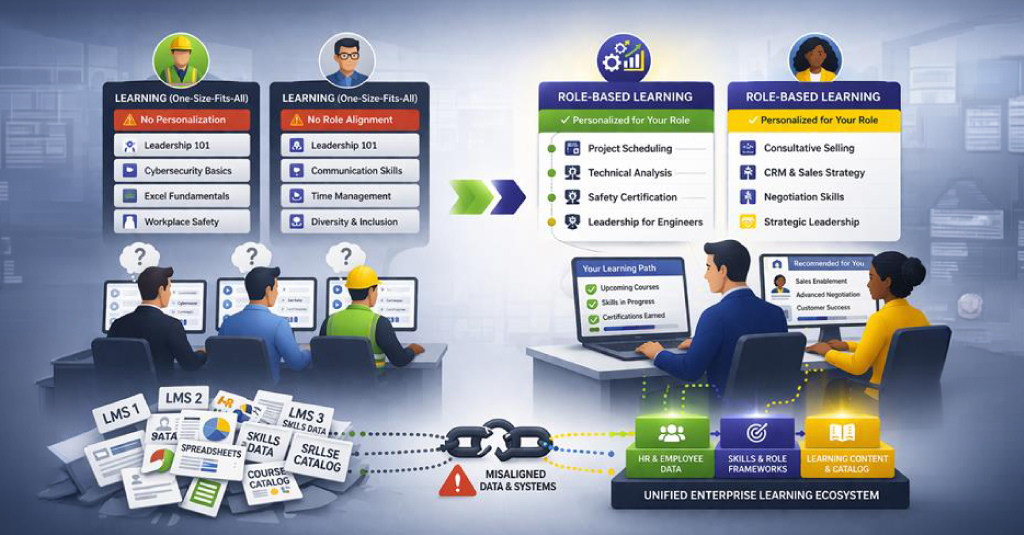
So, my premise for the past couple of decades is to decouple what learners see from how it’s delivered. That is, have discreet learning ‘objects’, and then pull them together to create the experience. I’ve argued elsewhere that the right granularity was by learning role: concepts are separate from examples, from practice, etc. (I had team members participating in the standards process.) The adaptive platform was going to use these learning objects to customize the sequence for different learners. This was both within a particular learning objective, and across a map of the entire task hierarchy.
The way the platform was going to operate was typical in intelligent tutoring systems, with a twist. We had a model of the learner, and a model of the pedagogy, but not an explicit model of expertise. Instead, the expertise was intrinsic to the task hierarchy. This was easier to develop, though unlikely to be as effective. Still, it was scalable, and using good learning science behind the programming, it should do a good job.
Moreover, we were going to then have machine learning, over time, improve the model. With enough people using the system, we would be able to collect data to refine the parameters of the teaching model. We could possibly be collecting valuable learning science evidence as well.
One of the barriers was developing content to our specific model. Yet I believed then, and still now, that if you developed it to a standard, it should be interoperable. (We’re glossing over lots of other inside arguments, such as whether smart object or smart system, how to add parameters, etc.) That was decades ago, and our approach was blindsided by politics and greed (long sordid story best regaled privately over libations). While subsequent systems have used a similar approach (*cough* Knewton *cough*), there’s not an open market, nor does SCORM or xAPI specifically provide the necessary standard.
Artificial intelligence (AI) has changed over time. While evolutionary, it appears revolutionary in what we’ve seen recently. Is there anything there for our purposes? I want to suggest no. Tom Reamy, author of Deep Text, argues that hybrids of symbolic and sub-symbolic AI (generative AI is an instance of the latter) have potential, and that’s what we were doing. Systems trained on the internet or other corpuses of images and/or text aren’t going to provide the necessary guidance. If you had a sufficient quantity of data about learning experiences with the characteristics of your own system, you could do it, but if it exists it’s proprietary.
For adaptive learning about tasks (not knowledge; a performance focus means we’re talking about ‘do’, not know), you need to focus on tasks. That isn’t something AI really understands, as it doesn’t really have a way to comprehend context. You can tell it, but it also doesn’t necessarily know learning science either (ChatGPT can still promote learning styles!). And, I don’t think we have enough training data to train a machine learning system to do a good job of adapting learning. I suppose you could use learning science to generate a training set, but why? Why not just embed it in rules, and have the rules work to generate recommendations (part of our algorithm was a way to handle this)? And, as said, once you start running you will eventually have enough data to start tuning the rules.
Look, I can see using generative AI to provide text, or images, but not sequencing, at least not without a rich model. Can AI generate adaptive plans? I’m skeptical. It can do it for knowledge, for sure, generating a semantic tree. However, I don’t yet see how it can decide what application of that knowledge means, systematically. Happy to be wrong, but until I’m presented with a mechanism, I’m sticking to explicit learning rules. So, where am I wrong?
This blog was originally published on Learnlets.